Introducción
En el mundo de la inteligencia artificial, pocas innovaciones han tenido un impacto tan profundo como la arquitectura Transformer. Desde su presentación en 2017 por Vaswani et al. en el artículo “Attention is All You Need”, los Transformers han transformado —literalmente— la forma en que las máquinas entienden y generan lenguaje. Esta arquitectura no solo ha superado a sus predecesores en rendimiento, sino que ha permitido el surgimiento de los modelos de lenguaje grandes (Large Language Models, o LLMs), que hoy protagonizan una nueva era de interacción entre humanos y máquinas.
Pero ¿qué hace que los Transformers sean tan especiales? ¿Por qué son la base de modelos como GPT, BERT, PaLM o LLaMA? Y sobre todo, ¿cómo han influido en el diseño, entrenamiento y capacidades de los LLMs modernos?
Antes de los Transformers: un vistazo al pasado
Antes de los Transformers, el procesamiento de lenguaje natural (NLP) dependía de arquitecturas como las redes neuronales recurrentes (RNN) y las LSTM (Long Short-Term Memory). Estos modelos procesaban el texto palabra por palabra, en orden secuencial, lo que limitaba su capacidad para capturar relaciones a largo plazo entre palabras y hacía que el entrenamiento fuera lento y difícil de paralelizar.
Por ejemplo, entender la relación entre “Luis” y “él” en una frase larga requería que el modelo mantuviera en memoria esa conexión durante muchas etapas. Las RNN sufrían de problemas como el desvanecimiento del gradiente, lo que dificultaba el aprendizaje de dependencias lejanas.
El nacimiento del Transformer
El Transformer rompió con esa tradición. Su arquitectura se basa en el mecanismo de atención, que permite al modelo enfocarse en diferentes partes de la entrada simultáneamente. En lugar de procesar el texto de forma secuencial, el Transformer lo analiza en paralelo, considerando todas las palabras a la vez y ponderando su relevancia entre sí.
Este enfoque tiene varias ventajas:
- Paralelización: El entrenamiento puede distribuirse eficientemente en múltiples GPUs.
- Contexto global: El modelo puede entender relaciones entre palabras sin importar su distancia.
- Escalabilidad: Se pueden construir modelos con miles de millones de parámetros.
¿Qué es la atención?
El mecanismo de atención es el corazón del Transformer. Imagina que estás leyendo una frase como: “Luis dejó su libro en la mesa porque él tenía prisa.” Para entender que “él” se refiere a “Luis”, necesitas prestar atención a esa parte de la frase. El Transformer hace algo similar: calcula cuánto debe “atender” cada palabra a las demás en función de su relevancia contextual.
Este mecanismo se implementa mediante matrices llamadas queries, keys y values, que permiten al modelo calcular pesos de atención entre palabras. El resultado es una representación rica y contextualizada del texto.
Arquitectura Transformer: bloques fundamentales
Un Transformer típico está compuesto por:
- Embeddings: Representaciones vectoriales de las palabras.
- Capas de atención multi-cabeza: Permiten al modelo enfocarse en múltiples aspectos del texto simultáneamente.
- Capas feed-forward: Redes neuronales que procesan la información después de la atención.
- Normalización y residuals: Mejoran la estabilidad del entrenamiento.
Esta arquitectura se repite en múltiples capas, lo que permite al modelo aprender representaciones cada vez más abstractas y poderosas.
El auge de los LLMs
Gracias a los Transformers, fue posible entrenar modelos de lenguaje a gran escala. Aquí algunos hitos:
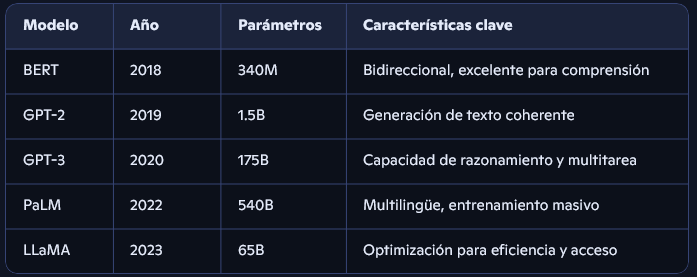
Estos modelos no solo entienden el lenguaje, sino que pueden generar texto, traducir, resumir, responder preguntas, escribir código y mucho más.
Preentrenamiento y ajuste fino
Los LLMs se entrenan en dos fases:
- Preentrenamiento: El modelo aprende patrones del lenguaje a partir de enormes cantidades de texto (libros, artículos, sitios web).
- Fine-tuning (ajuste fino): Se especializa en tareas concretas, como responder preguntas médicas o redactar correos.
El Transformer permite que esta transferencia de conocimiento sea eficiente y efectiva.
¿Por qué los Transformers son ideales para LLMs?
- Flexibilidad: Pueden adaptarse a múltiples tareas sin necesidad de rediseñar la arquitectura.
- Escalabilidad: Funcionan bien incluso con cientos de miles de millones de parámetros.
- Generalización: Aprenden representaciones que se transfieren a tareas nuevas con pocos ejemplos (few-shot learning).
- Multimodalidad: Se han extendido a modelos que procesan texto, imágenes, audio y más.
Innovaciones derivadas
La arquitectura Transformer ha inspirado variantes como:
- Encoder-only: BERT, para tareas de comprensión.
- Decoder-only: GPT, para generación de texto.
- Encoder-decoder: T5, para tareas de traducción y resumen.
También ha dado lugar a mejoras como:
- Sparse attention: Para manejar secuencias más largas.
- Retrieval-augmented models: Que combinan memoria externa con generación.
- Mixture of experts: Que activan solo partes del modelo según la tarea.
Impacto en la sociedad
Los Transformers han impulsado aplicaciones que ya forman parte de nuestra vida diaria:
- Asistentes virtuales: Como el que estás usando ahora .
- Traducción automática: Más precisa y contextual.
- Educación personalizada: Tutores virtuales que se adaptan al estudiante.
- Medicina: Apoyo en diagnóstico y análisis de textos clínicos.
- Creatividad: Generación de música, arte y literatura.
Desafíos éticos y técnicos
Con gran poder viene gran responsabilidad. Los LLMs basados en Transformers enfrentan retos como:
- Sesgos: Reflejan prejuicios presentes en los datos de entrenamiento.
- Desinformación: Pueden generar contenido falso con apariencia creíble.
- Consumo energético: Entrenar modelos gigantes requiere recursos masivos.
- Privacidad: Riesgo de que memoricen datos sensibles.
La comunidad trabaja activamente en mitigar estos problemas mediante técnicas como red-teaming, differential privacy y alignment.
El futuro: ¿qué sigue?
Los Transformers siguen evolucionando. Algunas tendencias actuales incluyen:
- Modelos más eficientes: Como los TinyML para dispositivos móviles.
- Modelos multimodales: Que combinan texto, imagen, audio y video.
- Modelos interactivos: Capaces de razonar, dialogar y aprender en tiempo real.
- IA alineada con valores humanos: Para garantizar seguridad y utilidad.
Conclusión
Los Transformers no solo han influido en los LLMs: los han hecho posibles. Su arquitectura ha permitido escalar la inteligencia artificial a niveles antes inimaginables, abriendo la puerta a una nueva era de comunicación entre humanos y máquinas. Desde Luis en Albacete hasta investigadores en Tokio, todos estamos viviendo el impacto de esta revolución silenciosa pero poderosa.